cogier wrote: ↑Tuesday 24th September 2019 12:56pm
Thanks Godzilla. I am also excited by the possibilities this feature opens up.
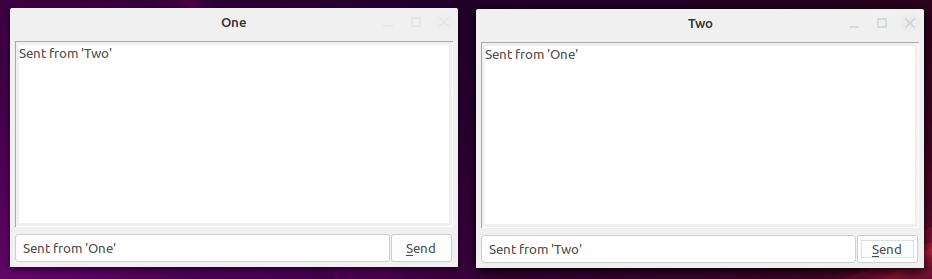
I was also interested in your original question and came up with these 2 programs named 'One' and 'Two' (original naming don't you think! ). They will pass a string between themselves, but could be altered to send arrays.
One.tar.gz
cogier, you nailed it! I had a lot of fun experimenting with this very simple method of program communication you demonstrated.
I've combined all your code examples and I hope you'll find alterations I've done interesting. I've changed things around a bit, for the sake of bench marking. We know this is a great leap forward in computation. I just wanted to get a feel for how much so.
I've put 3 buttons on your project.
The first button I've renamed "Task / Multi-Core" which uses your Task method to crunch the 4 sets of numbers, which I've put into additional text boxes on the form. The numbers are easily changed, to assist in testing. The time to complete is bench marked.
The middle button I've named "Satellites / Parallel" which activates the four running "satellite" programs (I decided "satellite" is a better terminology than "slave"). Using your method of file communication, each satellite is activated to crunch those same 4 sets of numbers in parallel. The time to complete is bench marked.
The third button "One Core" simply crunches those same 4 sets of numbers in the conventional sequential manner, using a single core. The time to complete is bench marked.
Here's my bench mark results with the default 4 sets of numbers on one of my computers:
00d 00h 00m 15s for task Using all 4 cores
00d 00h 00m 16s for task Satellite / Parallel
00d 00h 00m 38s for task Using only 1 core
As you can see, your Task method is faster than my satellites method. I think its due to the extra overhead of the text file communication, not to mention the four other running programs. However, either method leaves the sequential number crunching in the dust. Revolutionary!
As a side note, I got some mismatch errors using CInt with some of the text communication files. At first I changed all Integers in the programs to Long. This eliminated the errors. But it turned out that Longs take twice the time to calculate. So I went back and changed everything to Integer, and kept the numbers within limits. And everything now functions happily.
Thanks again cogier for your latest code example. And I hope you'll find what I've done with your examples interesting.
Edit: the two additional satellite programs are attached in the next message, four satellites total.
cogier wrote: ↑Wednesday 25th September 2019 2:04pm
I'm not sure I understand what I am supposed to do. I don't seem to have the extra buttons all I have is as below. Did I do something wrong?
Hey cogier,
With "TaskCPUMax_Godzilla", its all been altered slightly, for the sake of benchmarking. We're using 3 approaches to crunching four sets of numbers. There's your Task method invoking four CPU cores, my method using four satellites that work in parallel, and the traditional method of using 4 loops one after the other in sequence.
We want to compare which of these 3 methods completes a counting task, using the same sets of numbers, in the least amount of time. As such, we're not particularly interested in the results of the counting, but simply the time it takes for each method to complete, for the sake of a benchmark. The lowest time will be better.
How the satellites work is, they only need to be running, in conjunction with "TaskCPUMax_Godzilla" also running. I used multiple instances of the Gambas IDE to allow this.
The satellites are set up so that they're dormant and waiting on you to press the "Satellites / Parallel" button on the "TaskCPUMax_Godzilla" form. Doing so creates files in the /tmp folder, which the satellites will detect using timers. Each satellite will then acquire a specific and different number to crunch, and will begin crunching automatically, without user input. Once "TaskCPUMax_Godzilla" has detected that all four satellite tasks have been completed (reporting back is automated, requiring no user input), then "TaskCPUMax_Godzilla" will give a benchmark for overall time it took for all satellites to complete this task of crunching 4 sets of numbers.
After reporting back, the satellites reset themselves and go back into a dormant state, awaiting for you to press the "Satellites / Parallel" button again, Maybe this time with a different set of numbers, for testing purposes. Again, in this case, "TaskCPUMax_Godzilla" is not at all interested in receiving specific data back from the satellites. Only an indicator of when each task is completed, for the sake of producing a time benchmark for this parallel / satellite method of crunching sets of numbers vs other methods.
cogier I'm sorry I wasn't clearer in my last post. I hope this helps you and anyone else who's been following this thread.
No it was me . I did not run 'TaskCPUMax_Godzilla'. I got very similar results as you 15, 16, 36 secs which shows that the 'Task' method is the easiest and the best.
You could also make a Class for each of the tasks you need to complete if the tasks are not the same.
Tip: - If you want to put Gambas code on the Forum use the 'gb' button and you will get: -
cogier wrote: ↑Thursday 26th September 2019 1:42pm
No it was me . I did not run 'TaskCPUMax_Godzilla'. I got very similar results as you 15, 16, 36 secs which shows that the 'Task' method is the easiest and the best.
You could also make a Class for each of the tasks you need to complete if the tasks are not the same.
Tip: - If you want to put Gambas code on the Forum use the 'gb' button and you will get: -
Hey cogier, I'm glad you got the code working. I should have put all 5 project folders into the same archive, since they're closely related. But I didn't know if that was permitted.
Definitely the Gambas code button looks much better. From now on.
I'm very much looking forward to utilizing your Task method with calling and running different subs in parallel. Thank you for your advice to put them into classes. That's where I'll begin. I'll have time over the weekend to lose myself in it.
And even though satellite parallel processing is now obsolete, I'm looking forward to learning the methods of program communication given in vuott's link. Just because I find it fascinating.
So I figured out a way to get the Task method to call 4 subroutines in parallel. It works astonishingly well. I couldn't have asked for a better solution to my original post.
However, there's one problem I can't figure out. The subroutines called by the Task process simply sort various fields of public class arrays, and put the results into other receiving public class arrays. It works completely as expected. Except, once all the parallel Task operations are completed, the receiving class arrays are inexplicably redimmed to empty arrays.
I'm sure its something scope-related. But for the life of me, I can't figure it out.
All you have to do with this program is press the "Go" button and watch the printed output in the console. All it does is, on Form_Open it generates a ton of random data (5,000 records) into a main class array. And then splits that data into 4 sub-category class arrays. The "Go" button initiates the Task processes, and calls subroutines that simply sort by the various fields of those 4 sub-category class arrays, and puts the sorting results into yet other class arrays.
Its all more complex than it needs to be. And its all database stuff, better handled by SQLite. But its intentional, to give the CPU something to briefly crunch on.
In the console, I have it set up to print a 4-record sample of each resulting class array, post-sort. The samples indicate that the data is there, and the sorting of various fields have been done correctly. But once the Task process has completed, those very same arrays immediately become inexplicably redimmed and empty.
Whatever is going on here is beyond me. Any help is appreciated. And thank you for your time.
I have spent an hour or so on this and can't find the answer. You need to make a simpler program. I think that you can only return items from the 'Task' and not try to use FMain in the 'Task'.
On another note you can change this routine to: -
Public Sub cmdGo_Click()
GetTickCount("start", "Using all 4 cores")
CPU1 = New CPU(1, 1) As "CPUs"
CPU2 = New CPU(2, 2) As "CPUs"
CPU3 = New CPU(3, 3) As "CPUs"
CPU4 = New CPU(4, 4) As "CPUs"
End
Then you can change Public Sub CPU1_Kill() to: -
Public Sub CPUs_Kill() '********************************************
'Public Sub CPU1_Kill()
Dim TextBoxes As TextBox[] = [TextBox1, TextBox2, TextBox3, TextBox4]
TextBoxes[Last.Value - 1].Text = "CPU task " & Last.Value & " Finished" '********************************************
'TextBox1.Text = "CPU task " & CPU1.Value & " Finished"
If TextBox1.Length > 0 And TextBox2.Length > 0 And TextBox3.Length > 0 And TextBox4.Length > 0 Then
GetTickCount("finish", "Using all 4 cores")
Print "** FINAL A_Sub **"
Print "A_SubCategory_ByDate.Max = " & A_SubCategory_ByDate.Max & " << Why have these class arrays been erased? Scroll up to see that they were full of records and data a millisecond ago. =/ A scope issue?"
Print "A_SubCategory_ByNumber.Max = " & A_SubCategory_ByNumber.Max
Print "A_SubCategory_ByTime.Max = " & A_SubCategory_ByTime.Max
Print "A_SubCategory_ByName.Max = " & A_SubCategory_ByName.Max
Print "** FINAL B_Sub **"
Print "B_SubCategory_ByDate.Max = " & B_SubCategory_ByDate.Max
Print "B_SubCategory_ByNumber.Max = " & B_SubCategory_ByNumber.Max
Print "B_SubCategory_ByTime.Max = " & B_SubCategory_ByTime.Max
Print "B_SubCategory_ByName.Max = " & B_SubCategory_ByName.Max
Print "** FINAL C_Sub **"
Print "C_SubCategory_ByDate.Max = " & C_SubCategory_ByDate.Max
Print "C_SubCategory_ByNumber.Max = " & C_SubCategory_ByNumber.Max
Print "C_SubCategory_ByTime.Max = " & C_SubCategory_ByTime.Max
Print "C_SubCategory_ByName.Max = " & C_SubCategory_ByName.Max
Print "** FINAL D_Sub **"
Print "D_SubCategory_ByDate.Max = " & D_SubCategory_ByDate.Max
Print "D_SubCategory_ByNumber.Max = " & D_SubCategory_ByNumber.Max
Print "D_SubCategory_ByTime.Max = " & D_SubCategory_ByTime.Max
Print "D_SubCategory_ByName.Max = " & D_SubCategory_ByName.Max
Endif
End
Now you can get rid of: -
Public Sub CPU2_Kill()
Public Sub CPU3_Kill()
Public Sub CPU4_Kill()
I really appreciate the time you took to look into this and search for a solution. I also appreciate the enhancements to the code to simplify the code. Tonight I'll add those modifications to the code and re-upload it for the benefit of others, but in a rush at the moment to get to work.
Yes, all I can imagine is FMain can't be called from the Task method. Maybe I have the right idea, but I'm approaching it incorrectly. There is a solution to this, and I'll figure it out if someone doesn't beat me to it.
The subroutines being called by the Task method are actually based on an old simple Visual Basic routine, posted in some forum, on how to sort a simple array. I believe someone asked why they were getting an error using that routine to sort a structured array (where each array index has a set of fields instead of a single value). A reply was "that can't be done." When it comes to programming, I've never taken "no" for an answer LOL. I worked on that routine, and got it working beautifully for sorting structured arrays, as demonstrated in the code. Even if it is somewhat CPU-intensive (which is exactly what i was looking for ).
If someone else doesn't beat me to it, in coming up with a working method of running subroutines in parallel using the Task method, I'll post it here when i figure it out. We're so close.
And I must give credit to cogier and his friend for letting me know that the Task method even existed, along with an example project to work with.
FYI, in this post I use Task, Fork, parallel processing, multi-processing interchangeably. Its all referring to the same thing.
In my earlier experimental project Task_Test, everything worked great. Except for one huge problem.
Public/Global arrays that were filled with hundreds of sorted records (proven with Print statements), called from within the Task/Fork processes, became inexplicably reset to Null, the instant the Task/Fork processes completed.
After looking into this matter, it turns out that Fork processes are copies of parts of the parent Gambas program, which are given over to the system, thereby allowing multi-processing to occur. The problem with this is, these Forked processes don't appear to have any way to communicate the results of their work back to the parent Gambas program. The Forks complete their duties, then POOF they're gone. Along with any variables containing post-processed data your Gambas program may have been expecting.
Well, if we can't get any post-processed work out of the Fork processes, then what good are they? (I know, right?) But, I've come up with a working solution, thanks to cogier. One simply needs to File.Save the post-processed resulting variable from within the Forked process, and then File.Load that saved variable into your Gambas program. This gives you all the benefits of multi-processing without Gambas needing to strictly have built-in support for it.
All fine and good. But what if the resulting variable is an array? What if its a monster structured class array from h*ll, like Godzilla has a fondness for working with, in his Task_Test project? Something like that is beyond the capabilities of File.Save and File.Load.
I thought I was out of luck. However, I've found a solution thanks to code posted by Jussi Lahtinen in 2013. Object serialization, which is just a fancy term for a way of saving and loading variables of essentially infinite complexity, using very fast binary files (the routines are SaveValues and LoadValues). So thanks to Jussi, Task_Test is now a 100% working project, updated here as Task_Test_Working.
Jussi's SaveValues and LoadValues routines were, however, incomplete. In that they were missing support for the variable types: Single, Float, Variant, Object, and Pointer. I've completed his routines to include all that were left out. I haven't strictly tested each of these additional variable types. But in theory, any variable type of any level of complexity you can throw at SaveValues and LoadValues should work.
Instructions for the Task_Test_Working project:
When you run the program, it will tell you how many threads your CPU is capable of using. "Available CPU threads: 8" for me, though 4 are hyper-threads which is fine. Pressing the Go button will generate a structured array containing 5000 (by default) records generated at random. You can change it to whatever number you like in the textbox. Higher numbers increase the duration of CPU load (exponentially) and lower numbers decrease the duration of CPU load. Once you decide on a new number, simply press Go again (pressing Go additional times has been fixed).
Assuming your CPU has 4 cores or hyper-threads, you can watch all the various subroutines being computed in parallel on your System Monitor > Resources Tab > CPU History graph. Fantastic!
If you tick the Parallel vs. Sequential checkbox, then press the Go button, it will run a normal multi-process Task, and print a time benchmark in the console on completion. Immediately after, it runs the exact same set of data using the exact same subroutines, but in sequence, and also giving a time benchmark in the console on completion.
Parallel vs. Sequential's two time benchmarks allow you to see and appreciate how much time you save using parallel processing over sequential processing, when it comes to CPU-intensive processes. I didn't do extensive tests, but it seems the time saved using multi-processing seems to increase as the number of records you choose to process increases. But I don't really know. Play around with it if you like. Run a controlled series of tests to find out whatever there is to find out.
You can, of course, call any set of subroutines to run in parallel that you want. Your subroutines don't have to use Public/Global variables (scope is immaterial in Forked processes), they don't have to return complex variables or arrays, and you don't have to use the SaveValues and LoadValues routines. You may not want any information returned from Fork processes at all. Just use it however it would be beneficial to you, if you need powerful computing done as quickly as possible.
As it is in this project, the Task method is hard-coded to use 4 threads, regardless of your CPU capability. It would be a nice addition to this code if the number of threads could be assigned dynamically according to how many are available to the CPU.
Also, let's say you have 16 CPU-intensive subroutines to call. I'm not sure how one could "queue" subroutines and have them be executed as CPU threads become available. It would be very interesting to be able to do this.
So there's much more to multi-processing in Gambas to think about. But at least we have our foot in the door now. This thread is very happily [SOLVED] thanks to cogier and his friend. But lets continue to develop and build on ideas for Tasking/Forking. Its something I couldn't be happier with or excited about.
Feel free to ask questions if you're trying to implement any of this into your own project. We're here to help.

). They will pass a string between themselves, but could be altered to send arrays.
 TaskCPUMax_Godzilla.tar.gz
TaskCPUMax_Godzilla.tar.gz